We trained teams from



Google and AI are both data science problems.
Most agencies are not data science companies.
We map the authority layer of the internet.
We design citation systems for generative search. We engineer AI citation probability.
We engineer the authority infrastructure that determines who Google ranks and who AI recommends.
The model everyone is still selling stopped working in 2021. The 2024 Google API leak confirmed it. Most agencies are still reporting the metric your agency uses — not one of the signals Google actually ranks you on. We work in all three. Relevance, real traffic, topical coherence.
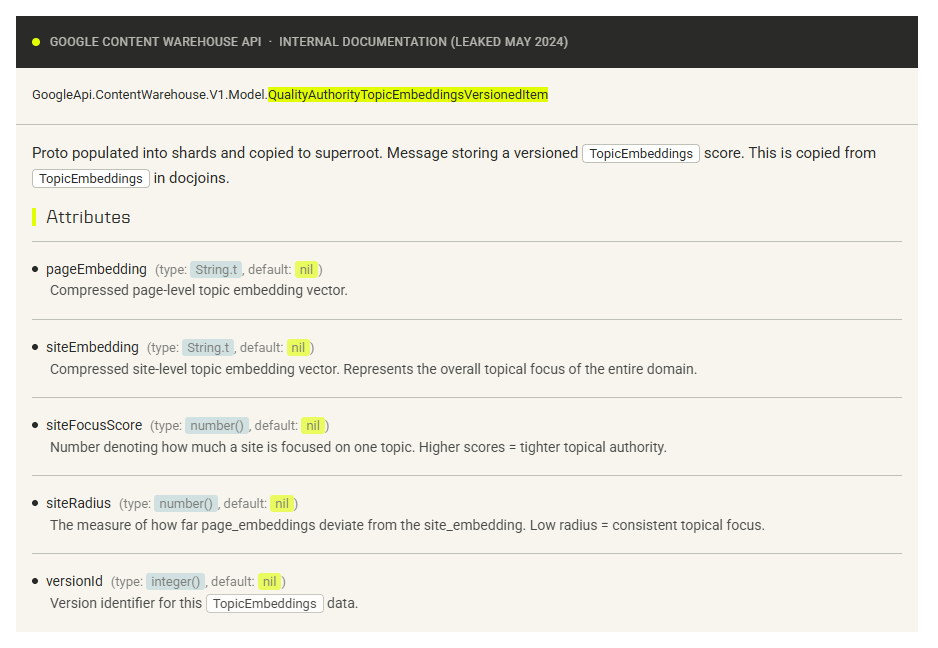
The signals Google actually uses
What the 2024 Google API leak revealed
In 2024, Google’s Content Warehouse API was publicly leaked and independently documented. It exposed the production fields Google’s ranking pipeline uses.
These are not theoretical. They are the actual field names from Google’s own codebase:
- **siteFocusScore** — how topically focused the linking site is. A site publishing across 40 unrelated topics passes less authority than one tightly focused on your niche.
- **siteEmbedding / pageEmbedding** — vector representations of the linking site and page. Semantic signals, not keyword matches.
- **context2** — a hash of the terms in the paragraph surrounding the link. The paragraph context outweighs the anchor text.
- **sourceType** — quality tier of the linking page: HIGH, MEDIUM, or LOW. Domain Rating does not appear in this list.
- **anchorMismatchDemotion** — a penalty applied when the anchor topic does not match the destination page.
- **siteRadius** — how far individual pages drift from a site’s topic centroid. High drift = lower authority weight.
The leak exposes that these fields exist and are active in the pipeline. It does not publish Google’s exact weights. WLDM’s scoring model is built on these fields — not on DR, not on link counts.
How WLDM engineers against these signals
WLDM’s Cosine Scorer maps directly to the three highest-weight leak signals:
score = 0.50 × cos(context_paragraph, target) ← context2 + 0.30 × cos(referring_page_body, target) ← siteFocusScore / siteEmbedding + 0.20 × cos(anchor_text, target) ← anchor match
CS 0.6 passes 3× the authority of CS 0.2 from the same domain. WLDM builds to CS 0.2+ as the floor — every placement rejected below it.
Every linking URL is also verified for real page-level traffic before acquisition, grounded in the Reasonable Surfer Patent (US 7,716,225 B1), which weights a link by the probability a real user clicks it. Page-level traffic. Not domain traffic. Not DR.
The Cosine Scorer is public, browser-local, and runs the same model used in audits. Run your own links through it at cs.wldm.io
Four services. One authority infrastructure.
Google ranking and AI citation probability are different problems. They need different solutions. WLDM builds both — on-page and off-page, for Google and for AI.
Backlinks
Off-page authority for Google ranking. Every source is scored for topical relevance, real traffic, and ranked page alignment before a single email goes out. Not link packages. Defined outcomes.
GEO
On-page structure for generative search. Makes your content readable, indexable, and citable by AI systems — so you show up in the answer, not just the index.
Book a strategy
session
One session. Your authority
gaps mapped. No pitch deck.
Get a strategy built
on your data
landscape. No generic recommendations.
Start with a 3-month
project. Results first.
outcomes. Stake.com doubled
traffic in 90 days.
Built on research no other agency has
Over 2,000 hours of AI citations research
The methodology behind the citation study
WLDM’s citation research ran from August to November 2024, in partnership with DataForSEO, across ChatGPT and Gemini. Every citation URL was normalised and enriched with authority metrics, real traffic data, schema presence, content type, freshness scores, Harmonic Centrality (extracted from the Common Crawl graph), and three cosine similarity measurements per citation.
Statistical analysis ran in two tracks: Spearman correlation of citation rank against each feature, and a cited-vs-not classification against SERP-controlled negatives. ChatGPT and Gemini were run separately to produce a defensible side-by-side comparison. A new study is currently running with Search Atlas and Surfer SEO. WLDM’s internal finding: an exploratory 10,000-citation set reproduces the patterns of the million-plus set, so scale is for publishability, not for the result.
The leak exposes that these fields exist and are active in the pipeline. It does not publish Google’s exact weights. WLDM’s scoring model is built on these fields — not on DR, not on link counts.
World's largest link-building database
600,000 domains. Half a million vectorised.
WLDM operates a proprietary link database of approximately 600,000 domains, roughly half a million vectorised for semantic scoring. It is the largest agency-side database of its kind.
Every keyword list runs through three phases: extract, clean, and enrich — completed in approximately 24 hours. The output is a scored opportunity list with roughly 40% expected conversion. Each domain is pre-classified by the ML pipeline before it reaches the targeting stage, so the list that arrives for outreach has already had the low-quality candidates removed.
Proof of coverage: a random sample of real AI citations run against the database returned a hit rate of approximately 7–8%, versus an expected baseline of around 1%. A Surfer SEO test across 90,000+ domains and 247,000+ URLs achieved approximately 8% hit rate at 40% conversion — confirming the database is meaningfully stronger than a naive baseline for citation acquisition as well as backlink acquisition.
The leak exposes that these fields exist and are active in the pipeline. It does not publish Google’s exact weights. WLDM’s scoring model is built on these fields — not on DR, not on link counts.
9 proprietary tools in the WLDM SEO + AI
citation toolkit
Two are public. Seven are internal.
The two public tools are available free, run in the browser, and use the same models as WLDM’s internal pipeline:
- AI Citations Audit — forces live ChatGPT searches across buyer-intent queries for a domain, builds the co-citation graph, computes Harmonic Centrality for every cited domain, outputs authority tiers (Dominant / Established / Emerging / Peripheral), and generates a prioritised placement plan.
- Backlink Relevance Cosine Scorer — scores semantic alignment between two URLs using the three-signal model grounded in the 2024 Google API leak fields. Runs entirely in the browser. No data leaves the device.
The seven internal tools include the ML backlink classification pipeline (five parallel classifiers, 3-of-5 voting), the Harmonic Centrality analyser applied to both the link graph and the co-citation graph, the opportunity extraction and enrichment pipeline, and the proprietary citation data pipeline built on the 11M+ study dataset.
Machine Learning Backlink classifying models at 99%+ accuracy
Five models. 18,000 training domains. 3-of-5 voting system.
WLDM’s ML backlink classifier was trained on 9,000 link-farm domains versus 9,000 quality domains, manually curated. Training used an 80/20 train/test split with k-fold cross-validation, deploying only when accuracy exceeded 90%.
Four parallel BERT processes run on each candidate domain: named entity extraction, keyword extraction, sentiment analysis, and feature engineering. The resulting entity cloud is what the classifier actually reads — a quality site’s entities form a tight, topically coherent cluster; a link farm’s scatter into semantic chaos.
| Classifier | Accuracy |
|---|---|
| Logistic Regression | 98.97% |
| Random Forest | 99.08% |
| SVM | 98.74% |
| MLP Neural Network | 99.31% |
| XGBoost | 99.31% |
A 3-of-5 voting system determines the final decision. No placement proceeds unless at least three models agree on classification.
World's First AI Citations Outreach Service
Same acquisition engine. Different selection math.
A backlink and an AI citation are the same page. The page that links to you for Google is usually the same page AI pulls from when it constructs an answer. Win the placement once, win both surfaces.
WLDM’s AI Citations outreach runs the same acquisition engine as its backlinks service, pointed at a different selection problem. What changes is the scoring math: instead of the Google link graph, WLDM scores against the co-citation graph and Harmonic Centrality, identifying the authority clusters LLMs treat as trusted sources in a category and acquiring placements inside them.
The workflow: run the AI Citations Audit to identify which domains are already being cited for the client’s target queries; filter for Harmonic Centrality tier (Dominant and Established first); cross-reference against WLDM’s link database for acquirability; score placement paragraphs by cosine relevance before any outreach begins.
Placement wording is deliberately varied across acquisitions because LLMs search the same question multiple ways and reassemble answers from fragments. A brand described the same way in 40 placements is weaker than the same brand described in varied, contextually accurate language — the retrieval model weights diversity, not repetition.
11M+ AI citations
analysed
The deepest citation study of its kind. The finding: AI cites the most connected brand, not the loudest.
WLDM’s citation study is the deepest of its kind — multi-model (ChatGPT vs Gemini), multi-signal (three cosine measurements, Harmonic Centrality, traffic, schema, freshness, content type), with statistical output at both the correlation and classification level. Conducted in partnership with DataForSEO.
Key findings:
- Most citations are noise. Only 10–20% of AI citations consistently reappear together as stable, recurring clusters. The rest cycle in and out. In a real client’s blackjack query cluster, 127 of approximately 3,000 cited domains appeared in nearly every answer — Brie named this the authority bubble.
- Personalisation is weaker than buyers assume. In a live room test, everyone who typed “best hotel to stay in Hawaii” into ChatGPT received the same two results, regardless of login status or browsing history. The same anchor sources recur across users and prompts.
- The Google and ChatGPT result sets barely overlap. WLDM’s own research confirmed approximately 12% overlap between what Google shows and what ChatGPT cites. Ranking number one on Google does not mean you exist in AI answers.
- 250 documents can change what a model believes. Anthropic research demonstrated it takes approximately 250 documents to shift a model’s position on a topic — regardless of whether the training set was 600 million or 13 billion documents. Brands that do not own their citation sources are vulnerable.

From below rank 30 to #1 for "Online Casino."
10 months. ML-driven. No shortcuts.
“Online Casino” — 85,000 monthly searches, keyword difficulty 95, $549,000 in monthly traffic value, requiring approximately 1,400 referring domains to compete in the top 10.
This is not a keyword you stumble into. This is a keyword you engineer your way to.
STARTING POSITION:
BELOW RANK 30
FINAL POSITION:
#1
TIMEFRAME:
10 MONTHS
Non-brand organic growth:
2x in 90 days
Keyword traffic value:
$549,000/month
Monthly searches:
85,000

Lucjan Suski
Surfer SEO
Dominykas Damalakas
NordVPN
Stephen Burns
Common Crawl
Peter Macinkovic
Stake.comWe built these tools to measure what
most agencies can't see.
We built these so you could see the methodology in action, learn how we think, and pressure-test it yourself. The internal tooling runs significantly deeper. These give you a working model of where we are.

If you've read this far, you probably saw me speak.
Good. That means you already know the methodology is real.
I’ve spent nearly twenty years in SEO and data science. I built WLDM because I got tired of watching good companies get sold reports instead of results. The research lab, the ML classifiers, the 11 million citation study. That’s how we actually work.
If something from the talk connected with what you’re dealing with, let’s talk it through. No pitch deck. Just your data.

